
ASCII x Microsft主催 第3回 AI Challenge Dayに当社のSmart Generative Chat開発チームから4名が参加し、見事グランプリを獲得いたしました!本記事では、前編に引き続き、AI Challenge Dayに対する当社の取り組みを、実際にメンバーとして参加した古城より、ご紹介します。
先に成果発表をご覧になりたい方は当日のアーカイブをどうぞ↓↓
それでは、振り返っていきたいと思います。中編のアジェンダはこちら↓↓
4.ユーザーインターフェース
前編で述べた通り、カスタマーストーリーや要件が整理できたため、ここから画面のイメージを考えます。なお、実装は最終日に急ごしらえでしたが、メンバーの頑張りもあって、WebApps上へのデプロイも含め、なんとな間に合わせることができました。
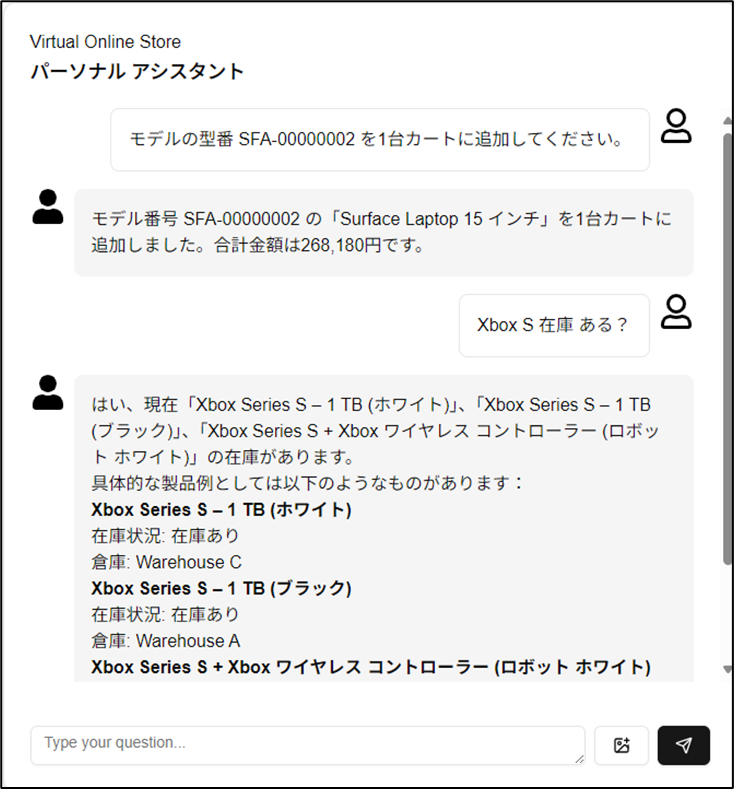
画面の作りはかなりシンプルになっていて、一般的なチャットボットのような形式です。
実は、AI Challenge Dayのお題は、1問1答の形式で、模範解答に近い返答が返ってくればOKというルールになっていました。しかし、カスタマーストーリーである「従業員が隣にいるような」を実現するには、機械的な1問1答形式ではなく、対話型のチャットボットとなるように実装をしています。
また、Reactコンポーネントとして開発を行うことで、既存サイトへの埋め込みも可能である、という点も含めての実装となりました。
5.RAG – データの取り込み –
さて、みなさんが最も気になっているであろう、RAGの実装について触れていきます。まずはデータソースの取り込みです。前編でもご紹介した通り、Azure AI Searchを中心にデータの検索を行います。Azure DatabaseやCosmos DBに対しても一部検索をかけながら適切な回答を導き出すことにしていますが、これらに関しては、機械的に登録しただけなので、ここではAzure AI Searchに焦点を当ててみていきます。
5-1. AI Searchの前提知識 - インデックス、インデクサー、スキルセット –
Azure AI Searchはさまざなデータソースを”インデックス“として登録し、それらに対して高度な検索をかけることができるAzure上のPaaSサービスです。インデックスはRAGを行う際のひとつの検索単位となります。インデックス登録は手動でもできますが、”インデクサー“という機能を使えば、自動的に対象の環境からドキュメントを取り込んでくれます。
インデクサーはひとつにつき、クローリング対象をひとつしか設定することはできませんが、ひとつのインデックスに対して、複数のインデクサーを登録することができるため、インデックスには複数のインデクサーが集めてきた情報を集約することができます。(わかりづらいので絵を参照)
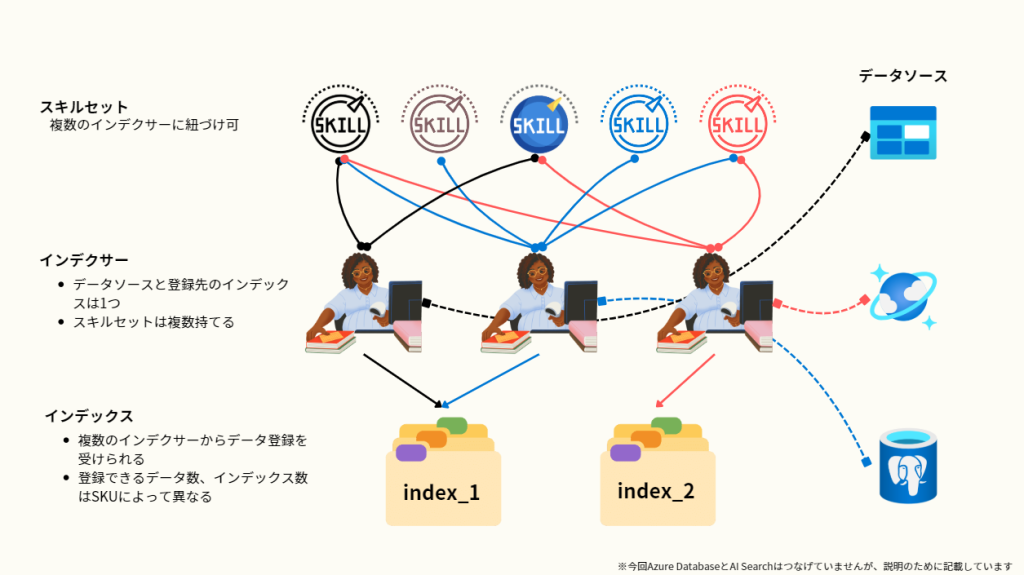
加えてインデクサーには”スキルセット“を付与することができます。スキルセットは、インデクサーのデータ取り込み時に、データに対する加工をどのように施すかを設定することができる機能です。スキルセットは標準でさまざまなものが用意されており、今回は感情分析スキルなどを活用しました。
この前提のもと、今回の我々の取り組みを見ていきます。
5-2. PDFファイルの読み込み
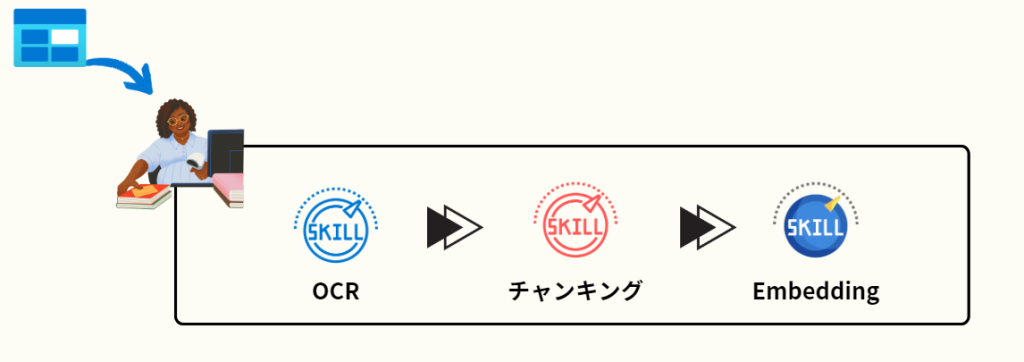
データセットの中には、PDFのデータが多数存在しました。これをAzure AI Searchに取り込む際に必須となるのが、ファイルのOCRです。OCRをして、その後データをチャンキング(文章を一定の文字数で分割)し、Embeddingの結果を各データに対して付与することで、検索精度やAI Searchが登録できるデータのサイズに適合させています。
この一連の流れは、AI Search側で提供されているスキルセットのテンプレートから選択するだけで、実装ができるようになっており、もっとも汎用性の高い機能であるともいえます。
5-3. つぶやきデータの登録
Cosmos DB上に、非構造化データとして提供されていたのが、X(旧Twitter)を想起させるSNSのつぶやきデータでした。部門2の分析をテーマとしたお題で利用するデータです。
X(旧Twitter)を思い出していただけばわかる通り、各つぶやきの内容はもちろんのこと、投稿日時、リツイート数、いいね数、ユーザー名やプロフィールといった情報が紐づいています。一見すると、AI Searchへの登録もすんなりできそうなデータでしたが、登録を実行してもエラーが起きてしまいました。
確認したところ、ユーザー情報のデータ型が異なることが原因でした。この場合、データをそのまま登録することができないので、登録時にデータの加工が必要となります。しかしながら、特定のデータに対するデータ型の変更は、当然スキルセットで標準的に実装されているものではありません。
そこで我々は、Azure Functions上にデータ型を変換する関数を実装し、インデクサーによるデータ取り込み時には「カスタムWeb API スキル – Azure Functions」を使用して、データ型を整えてから登録するように実装しました。これによりつぶやきデータのAI Searchへの登録も無事できるようになりました。
また、つぶやきデータの取り込みですが、もうひとつスキルセットを利用しています。それが感情分析のデータを付与する、というものです。
この点については、同様にスキルセットのテンプレートを使用して、各つぶやきに対して、ポジティブなのか、ネガティブなのか、ニュートラルなのかを判定させており、簡単に実装ができました。
5-4. 画像のEmbedding
データセットの中には画像のデータも存在していました。Azure AI Searchにはプレビューではありますが、画像のEmbeddingスキルもテンプレートで用意がされています。
しかしながら、今回はこのスキルの採用を見送ることとなりました。
今回は、画像だけではなく5-1で処理したようなドキュメントの情報も同じインデックス内で検索を行います。5-1では、text-Embeddingモデルを使用しており、画像のEmbeddingを別のモデルで行うと、優れた検索結果を出力できない場合があります。Embeddingモデルをそろえる必要があります。
そこで、画像の登録時に、各画像をGPTに読み取らせて説明文をつくり、その説明文をtext-Embeddingしてメタデータ的に付与してあげることで、すべて統一された形でベクトル化することにしました。これにより、無事データの種類が異なったとしても、適切に検索ができるようになりました。
5-5. AI SearchのSKU変更
Azure AI SearchにはいくつかのSKUが提供されています。今回、アーキテクチャの設計時点では、コストや想定しているインデクサーの数から、Basicプランを選択しました。しかし、ここである問題が発生します。
今回AI Search上にインデクサーを使って取り込むドキュメント群はすべてBLOBストレージに一度格納されています。しかしながら、AI Searchのクオータ制限を確認するとBasicプランのBLOBインデクサーが取得できる、「BLOB から抽出されたコンテンツの最大文字数」は64,000と制限されています。
つまり、64,000文字を超えるドキュメントがあった場合にはインデクサーによるデータの取り込みが失敗するということを意味します。
そして、今回この文字数を超えるドキュメントがありました。単純にBLOBにドキュメントを配置するだけではBasicプランのインデクサーは使えないということになります。
我々がデータを無事に登録するためにとることのできる選択肢は2つ
- BLOBへ配置する前に前処理を行う
- コンテストのルール上、手動でのデータ修正が禁止されているため、加工する仕組みを作る必要がある
- AI SearchのSKUをStandardプランへ変更する
- 現在インデックスに登録されている情報を移行(再登録)する必要がある
結果、コンテストの期間、コストを考慮し、後者のプラン変更を選択する形となりました。これで晴れてすべてのドキュメントをBLOBからAI Searchへ取り込むことができるようになったというわけです。
こうして、AI Searchに対してデータセットを登録することができました。あとはAI Searchのパワフルな検索機能をもとに質問に応じて必要な情報を抽出するのみとなります。後編では、もうひとつの主軸であるPrompt flowを使って、与えられたデータセットをどのように選択肢、回答させたのか、そして最終的なスコアはいくつになったのか、をご説明します。
ぜひ、ご覧ください!



